Cet article a été rédigé initialement sur le site bee4.fr. Il s’agit d’un article invité, publié ici pour maintenir le contenu.
Que font les robots des moteurs de recherche sur votre site ?
Lorsque les robots d’indexation comme GoogleBot, parcourent votre site web, ils laissent des traces. Ces traces sont stockées dans les logs du serveur web et peuvent être exploitées pour étudier leur comportement sur votre site.
Ces logs sont stockés sous forme de fichier et peuvent être configurés pour contenir toutes les informations utiles (statut HTTP, Referer, url ciblée, temps de réponse, UserAgent…). Toutes ces informations permettent de détecter “qui” visite le site à travers le UserAgent, quelles pages il a visité et comment le site a réagi lors de ce parcours.
Comment les outils SEO peuvent récupérer et stocker vos fichiers logs serveur ?
Ces fichiers sont stockés dans des espaces protégés sur le serveur et sont difficilement accessible de l’extérieur. Cependant plusieurs approches permettent de les extraire pour les exploiter :
- Périodiquement, les fichiers peuvent être copiés et compressés dans un espace dédié ;
- Installer un logiciel sur le serveur pour capturer les logs et récupérer ces informations ;
- Périodiquement le serveur peut envoyer les nouveaux fichiers vers une application externe.
Ces trois méthodes peuvent être mises en place sous plusieurs formes mais représentent les grandes familles de traitement pour accéder aux fichiers de logs. Aucune de ces techniques ne représente un problème en termes de sécurité car les espaces peuvent tous être protégés (HTTPS, SSH, FTPS, SFTP) par l’hébergeur.
Il est aussi possible que le serveur web soit utilisé pour motoriser plusieurs sites web. En fonction de la configuration utilisée, les logs de plusieurs sites peuvent être mélangés dans les mêmes fichiers. Pour les exploiter, il est donc important de réaliser une analyse préalable :
- Utiliser un outil permettant de séparer les logs en fonction du domaine du site ciblé et générer ainsi des fichiers spécifiques par domaine ;
- Utiliser un outil qui “écoute” les visites et transmet vers une application externe seulement les visites utiles ;
- Modifier la configuration du serveur web pour qu’il créée directement des fichiers par domaine.
Exploitation de la data des logs serveur : quels enjeux SEO ?
Mais suite à l’envoi des logs, quelles actions concrètes vont être menées pour l’amélioration du référencement naturel ?
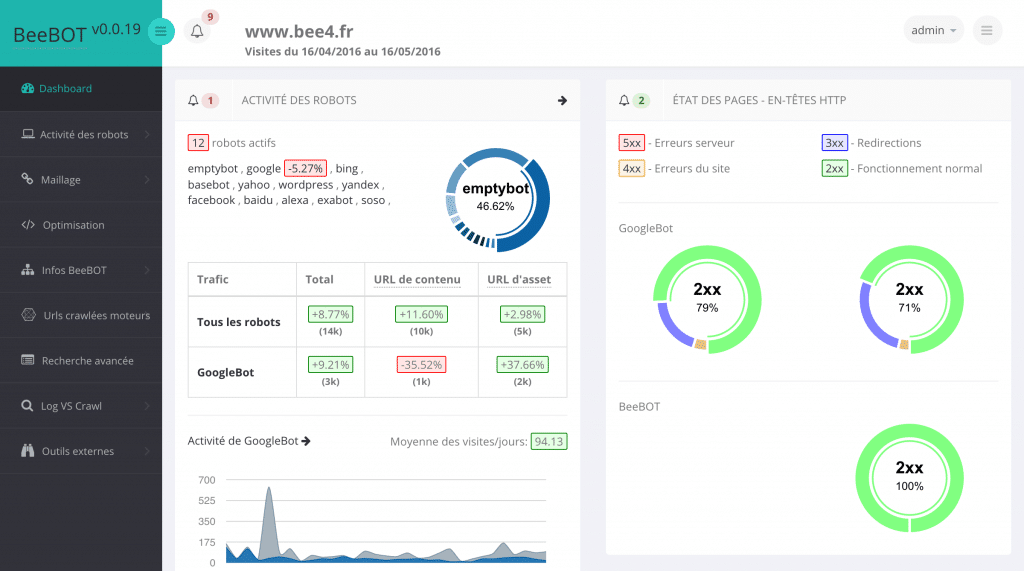
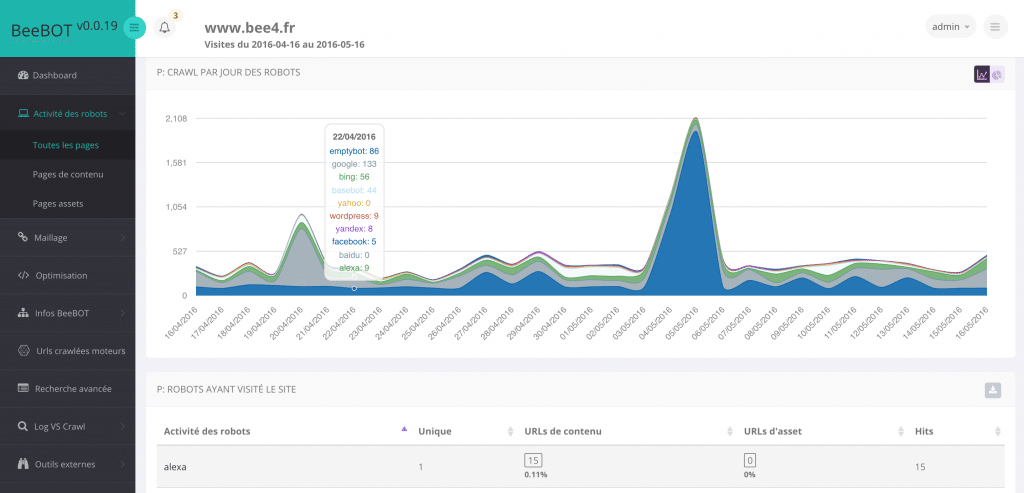
Tout d’abord, l’avantage principal est la connaissance poussée via une analyse détaillée du comportement des robots sur le site :
- Identification des robots les plus gourmands ;
- Identification des fréquences de passage globale et par robot, ainsi que par URL ;
- Analyse des codes HTTP reçus par les robots lors de leur passage dans le temps.
Ensuite, l’enjeu est de pouvoir corréler les informations utiles du crawl des robots (notamment de GoogleBot) avec des axes d’optimisations SEO.
Enfin, de manière indirecte, nous pourrions détecter toute activité anormale d’un robot ou programme espion sur votre site.
Besoin d’un conseil ou d’une vérification ?
BeeBOT, outil exclusif développé en partenariat avec l’agence Bee4 qui traite les logs serveur, sera bientôt commercialisé !
Déjà déployé en bêta-test chez certains clients, il permet une analyse fine du SEO. Contactez-nous pour plus d’informations !
Stéphane Hulard & Teodor Dachev
One comment
l’enjeu est de pouvoir corréler les informations utiles du crawl des robots (notamment de GoogleBot) avec des axes d’optimisations SEO.
Enfin, de manière indirecte, nous pourrions détecter toute activité anormale d’un robot ou programme espion sur votre site.