Cet article a été initialement publié sur la plateforme Medium. Il s’agit d’une traduction de l’article « Hype Driven Development » écrit par Marek Kirejczyk sur cette même plateforme.
Les équipes de développement prennent souvent des décisions à propos d’architectures logicielles ou de stack technique basées sur des avis biaisés, les médias sociaux, et en général sur ce qui est considéré cool, plutôt qu’en faisant des recherches solides et en prenant en compte l’impact que ça pourrait avoir sur leurs projets. J’appelle cette tendance « Hype Driven Development » ou HDD, considérez la comme mauvaise au profit d’une approche plus professionnelle que j’appelle « Ingénierie logicielle solide ». Apprenez en plus sur comment elle fonctionne et ce que vous pouvez faire à la place.
Nouvelle technologie — nouvel espoir
Avez-vous déjà vu ça ? Une équipe qui choisit la technologie la plus récente et tendance et qui l’utilise dans son projet. Quelqu’un a lu un article de blog, on en parle sur Twitter et nous revenons tout juste d’une conférence durant laquelle il y a eu une belle présentation à ce sujet. Peu après, l’équipe commence à utiliser cette super nouvelle techno (ou pattern d’architecture) mais au lieu d’aller plus vite (comme promis) et de construire un meilleur produit, ils ont pas mal de problèmes. Ils vont moins vite, sont démotivés, n’arrivent pas à livrer la prochaine version en production. Certaines équipes continuent de corriger des bugs au lieu de développer de nouvelles fonctionnalités. Ils ont besoin de ‘seulement quelques jours de plus’ pour tout sortir.
Hype Driven Development
Le « Hype Driven Development » se présente sous différentes formes et touche votre projet de bien des façons :
- Développement dirigé par Reddit — quand une équipe ou une personne décide d’une technologie/architecture/design en se basant sur ce qu’un blogueur populaire a écrit ou ce qui est tendance sur Reddit, HackerNews, Twitter, Facebook, GitHub ou tout autre réseau social.
- Développement dirigé par les conférences— regardez attentivement ce qui arrive aux personnes revenant de conférences. Ils sont inspirés. Et c’est à double tranchant. Commencer à utiliser la nouvelle librairie/framework/paradigme d’architecture sans faire assez de recherche peut se transformer en une vraie descente aux enfers.
- Décisions dirigées par le mec le plus fort — c’est quand une personne parle de ce nouveau framework/lib/tech, qu’il n’a aucune expérience avec, mais en parle tout de même tout le temps et que l’équipe décide de l’utiliser.
- Développement dirigé par des Gem/librairies/extensions — qui est particulièrement vrai dans la communauté Ruby On Rails, où je vois parfois un « Gemfile » si long que la seule chose la plus longue est le temps que met l’application à se charger. Ça vient de l’idée que tout problème avec rails doit être traité avec une Gem. Quelques-fois, ça ne nécessite que quelques lignes de code pour créer une solution nous même, mais nous préférons corriger le problème avec une librairie / extension / framework.
- Je voudrais aussi mentionner une pratique populaire chez les développeurs « Hype Driven » — Développement dirigé par Stack Overflow — que les développeurs copie/colle des solutions directement depuis Stack Overflow (ou en général depuis un site web) sans vraiment les comprendre.
HDD ou comment les équipes s’attirent elles-mêmes les problèmes
Le problème avec la tendance est qu’elle amène facilement à prendre de mauvaises décisions. Aussi bien de mauvaises architectures que de mauvaises stack techniques souvent remises en cause par une équipe plusieurs mois ou années plus tard. Dans le pire des cas, elles amènent à une situation vraiment problématique dans l’ingénierie logicielle : The Big Rewrite. Ce qui ne fonctionne presque jamais.
La source de tout le mal semble être les médias sociaux — où les nouvelles idées se développent plus vite qu’elles ne sont testées. Tellement vite que les gens ne peuvent pas comprendre leurs avantages et inconvénients.
Anatomie de la tendance
La plupart des tendances ont une structure similaire, la voici :
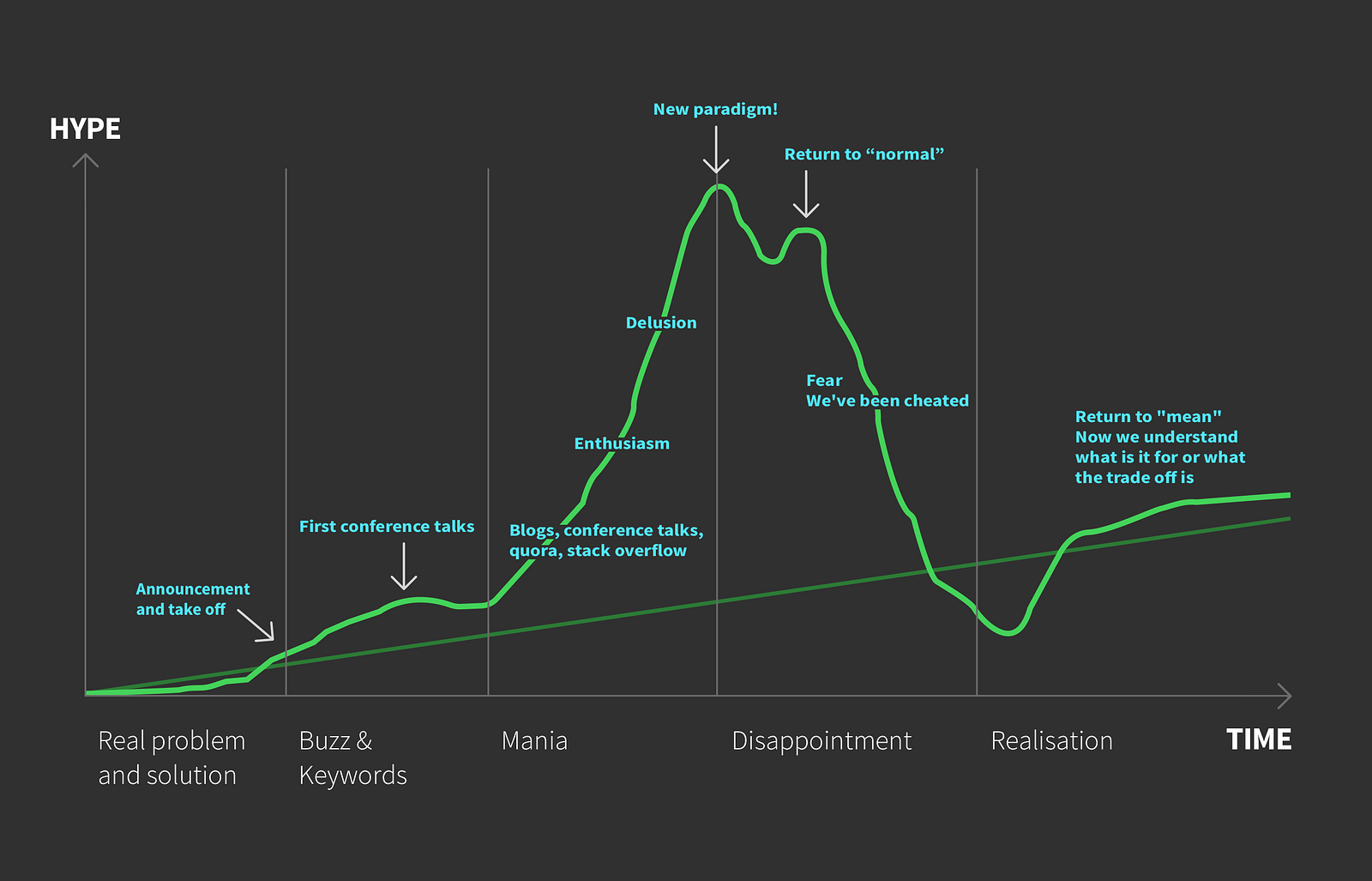
Étape 1 : Problème réel et solution
Elles commencent dans certaines entreprises avec un problème. Une équipe dans cette entreprise décide que la solution à ce problème est au-delà de ce qui se fait aujourd’hui en terme de techno / process / architecture. L’entreprise créée un nouvel outil / librairie / paradigme et bientôt le problème est résolu.
Étape 2 : Annonce publique, buzz et mots clés
L’équipe est excitée de montrer son travail au reste du monde et ils écrivent des articles de blogs, font des présentations dans les conférences. Le problème est souvent non trivial, ils sont donc fiers de présenter les résultats impressionnant de leur solution. Les gens commencent à aimer cette nouvelle technologie. Le seul problème est que toutes les personnes, qui trouve la solution intéressante, ne sont pas capables de vraiment comprendre quel était le problème et tous les détails de la solution. Il s’agit d’un problème complexe avec une solution complexe après tout. Ça demande plus d’un tweet ou d’un article de blog pour l’expliquer. Avec les outils de communications comme les médias sociaux, les blogs, et les lighting talks dans les conférences, le message devient flou avec le temps.
Étape 3 : La folie commence
Tout les développeurs « Hype Driven » commencent à lire les articles et participer aux conférences. Bientôt les équipes dans le monde entier commence à utiliser cette nouvelle technologie. A cause du flou dans le message, certaines prennent des décisions précipitées et utilisent le framework même s’il ne solutionne aucun de leurs problèmes actuels. Mais l’équipe croit que cette nouvelle technologie va l’aider.

Étape 4 : Déception
Les sprints passent la techno n’améliore pas le quotidien de l’équipe autant que souhaité, et demande beaucoup de travail supplémentaire. Il y a beaucoup de réécriture de code, de nouvelles connaissances à acquérir. L’équipe travaille moins vite, le management est énervé. Tout le monde se sent abusé.
Étape 5 : Prise de conscience !
Finalement, l’équipe fait une rétrospective et réalise quelles sont les contraintes de cette nouvelle technologie et à quoi elle pourrait être plus utile. Les développeurs deviennent plus sages… jusqu’à ce que la nouvelle tendance arrive.
Exemples de tendances
Examinons quelques exemples de tendances et voyons comment elles ont été gérées.
Exemple 1 : React.js
Étape 1 : Facebook a un problème, les applications complexes sur une seule page comme Facebook ont tellement d’évènement de changement d’état qu’il est difficile de toujours garder le fil et de maintenant stable l’état de l’application.
Étape 2 : Facebook fait la promotion d’un nouveau paradigme avec des mots tendances : fonctionnel, virtual DOM, composants.
Étape 3, Folie : Facebook a créé le framework front-end du future ! Il faut absolument tout écrire avec React maintenant !
Étape 4 : Attendez, il y a beaucoup de travail, mais pas un retour rapide sur investissement !
Étape 5 : React est utile pour des application web complexe avec beaucoup de notifications temps réel, mais n’est pas forcément adapté aux applications plus simple.
Exemple 2 : TDD is dead by DHH
Étape 1 : David Heinemeier Hansson (DHH, créateur du framework Ruby on Rails) réalise qu’il est difficile de pratiquer le TDD avec Rails parce que ce framework n’a pas une architecture adaptée. Il faut un choix pragmatique — ne pas écrire de tests à l’avance.
Étape 2 : La tendance démarre avec l’article de blog et la conférence de DHH. Mots clés : TDD est MORT.
Étape 3 : Notre Gourou nous dit : Passons nous des tests ! Nous ne les avions pas écrits de toute façon. Maintenant nous n’essayons même pas de prétendre l’avoir fait. Nous sommes finalement honnêtes.
Étape 4 : Attendez ! Il y a maintenant moins de choses qui fonctionnent qu’auparavant, nous avons écrit du code bugué !
Étape 5 : « TDD n’est pas mort ou vivant. TDD est soumis à des contraintes, incluant les risques de changement d’API, les compétences du développeur et la conception existante » — Kent Beck.
Exemple 3 : Micro-services
Étape 1 : Les applications monolithiques sont difficiles à faire grossir. Il y a un moment où il est opportun de séparer l’application en services. Ces services seront plus faciles à faire grossir en terme de requêtes/secondes et plus simple à gérer avec plusieurs équipes.
Étape 2 : Mot clés : scalabilité, découplage, monolithe.
Étape 3 : Il faut tout réécrire sous la forme de services ! Nous avons du ‘code spaghetti’ à cause de notre architecture monolithique ! Nous devons réécrire tout notre projet en micro-services !
Étape 4 : Argl ! C’est maintenant beaucoup plus lent de développer, difficile à déployer et nous passons énormément de temps à chercher des bugs à travers de multiples systèmes.
Étape 5 : Les micro-services demandent des compétences solides de dévops dans l’équipe et avec le bon investissement permettent d’arriver à une bonne façon de faire grossir le système et l’équipe. Avant de rencontrer de gros soucis de scalabilité c’est du surinvestissement. Les micro-services sont extrait, pas écrit. Vous devez avoir la taille réglementaire pour utiliser les micro-services.
Exemple 4 : NoSQL
Étape 1 : Les bases de données SQL ont des problèmes avec les fortes charges et les données non structurées. Les équipes du monde entier commence à développer une nouvelle génération de bases de données.
Étape 2 : Mots clés tendance : Scalabilité, Big Data, Hautes performances.
Étape 3 : Notre bases de données est tellement lente et pas assez grosse ! Nous avons besoin de NoSql !
Étape 4 : Nous avons besoin de joindre des tables ? Impossible. De simples opérations SQL deviennent incroyablement difficiles. Le développement est lent et notre problème principal n’est pas corrigé.
Étape 5 : Les bases NoSql sont des outils pour corriger des problèmes vraiment très spécifiques (soit des volumes de données très importants, des données non structurées ou de très fortes charges). SQL est un bon outil et est capable de gérer de fortes charges et de gros volumes de données correctement s’il est utilisé habilement. Les cas d’usage de NoSql sont encore assez rares en 2016.
Exemple 5 : Elixir et Phoenix (ou mettez votre couple language/framework préféré)
Étape 1 : Les framework web comme Ruby On Rails ne permettent pas de gérer correctement les applications à haute performance, les applications distribuées et les WebSockets.
Étape 2 : Mots clés tendance : Scalabilité, High Performance, Distribué, Tolérant aux pannes.
Étape 3 : Oh mon dieu, notre application est lente et notre chat n’est pas scalable !
Étape 4 : Wow, apprendre la programmation fonctionnelle et les approches distribuées n’est pas si simple. Nous sommes maintenant vraiment très lent.
Étape 5 : Elixir et Phoenix sont un bon framework, mais demande un gros effort d’apprentissage. Le retour sur investissement sera intéressant uniquement si vous avez besoin spécifiquement d’une application haute performance.
Cette liste grandit encore et encore
Dans ce monde surpeuplé d’ingénierie informatique, il y a beaucoup d’endroit où les tendances sont très courantes.
Dans le monde JavaScript, de nouveaux frameworks débarquent chaque jour. Node.js (programmation événementielle), reactive programming, Metor.js (état partagé), front-end MVC, React.js…
En ingénierie logicielle, de nouvelles architectures sont nées : Conception pilotée par le domaine, Hexagon, DCI. Quelle est votre tendance préférée ?
Bonnes pratiques
Donc, si on ne peut pas se fier à ce qui est dit sur Internet ni aux opinions d’autres personnes, comment fait-on pour prendre des décisions pertinentes ?
Tester et faites des recherches avant de décider
- Spikes — N’apprenez pas vos technologies à partir de blogs, mais de l’expérience. Prenez un ou deux jours pour construire le prototype d’une nouvelle fonctionnalité en utilisant cette nouvelle technologie avant de prendre la décision. Laissez l’équipe analyser les avantages et inconvénients. Il est conseillé de prendre plusieurs technologies similaires et de laisser plusieurs membres de l’équipe construire des prototypes avec ces différentes technologies.
- Les Hackathon sont une bonne façon de faire prendre conscience à une équipe des contraintes de différentes technologies. Prenez un ou deux jours et permettez à toute l’équipe de hacker toutes les technologies actuelles ou qui sont tentantes. Ce genre d’exercice permettre à l’équipe de prendre des décisions plus réfléchies et basées sur sa propre expérience.
Quand commencer ?
- En principe quand le retour sur investissement est important. La plupart des technologies sont créées pour résoudre un problème particulier. Avez-vous ce problème ? Est-ce que c’est un gros problème ? Est-ce que ça vous fera gagner beaucoup de temps ? Est-ce qu’utiliser cette technologie vaudra le coût d’apprentissage et la réécriture ? Que ce passera-t-il si nous devons diviser par deux l’effort de développement de l’équipe ? Par quatre ? Est-ce que ça vaut toujours le coup ?
- Les « bonnes » équipes sont autorisées à le faire souvent — certaines équipes sont juste plus rapides que d’autres à produire de la valeur. Elles s’ennuient avec ce qu’ils font plus facilement. Ces équipes peuvent introduire de nouvelles technologies plus souvent. Ce n’est pas une excuse pour ne pas utiliser les spikes et les hackatons. D’un autre côté, si l’équipe à des problèmes pour livrer son travail — procédez avec précaution.
Recrutez les bonnes personnes :
- Un bagage technique solide est votre ami — les gens qui, connaissant différents paradigmes, comprennent les théories de la programmation (e.g. algorithmes, parallélisation) et ont une bonne culture de l’ingénierie se laissent tenter moins facilement.
- Expérience — les tendances sont plus présentes chez les jeunes développeurs. Avec les années, les gens qui ont vu beaucoup de technologies et ont eu des tas de problèmes différents vont avoir tendance à être plus hésitants au moment de choisir une technologie.

4 comments
Hi,
I saw you tweeting about ai and I thought I’d check out your website. I really like it.
Have you thought of building a mailing list? I think people would really like to be signed up to what you have to share.
Dans le mobile, c’est hyper récurrent comme phénomène.
Il y a en premier lieu l’hybride qui est toujours la technologie hybride qui détrônera la technologie du constructeur. Démontrée par des POC de scenarii basiques. Et tous les 2 ans, un technologie hybride vient remplacer radicalement une autre. Flash Mobile, PhoneGap, Cordova, Ionic, React Native, Xamarin, Flutter…
Il y a aussi les technologies qui réinventent les technologies du constructeur : Realm en remplaçant de Core Data, Rx pour la programmation réactive, le code Swift fonctionnel poussé à l’extrême avec sa propre déclinaison du langage. Et autres approches impossibles à maintenir et à débogguer tout en explosant la consommation du matériel.
Hello Stéphane,
J’apprécie vraiment ton article et j’imagine que beaucoup s’y reconnaissent.
Arnaud Lemaire utilisait souvent le terme CV Driven Development, où l’équipe tech va embarquer une techno pour le mettre sur le CV, ça sera utile pour le prochain job ou la prochaine mission.
Effecivement, ça ne sert pas l’entreprise et le produit.
Par contre, je me rends compte que dans un contexe où les développeurs seniors sont difficiles à recruter et à fidéliser, laisser un peu de place pour qu’ils puissent se faire plaisir sur une techno de leur choix est un argument pour fidéliser ses équipes. En leur laissant la possibilité de choisir Elixir pour un nouveau service, parce que l’équipe a envie d’essayer, qu’ils ont fait un PoC et se sentent en mesure de l’accomplir, pourquoi pas ! Ce n’est pas le chemin le plus facile, il n’y a probablement pas plus de valeur à le faire dans ce langage plutôt que le langage historique, mais s’ils ont envie de se donner ce challenge et que ça contribue au bonheur de l’équipe dans la boite, je pense que c’es un choix qui n’est pas déconnant !
Qu’en dis-tu ?
Hello !
Et bien je pense que je te rejoins complètement !
Je ne suis pas du tout contre les nouvelles technos ou leur utilisation c’est plus les choix qui amènent à leur utilisation que je questionne.
Pour moi, une équipe va se construire, apprendre à connaître ses affinités, découvrir ses limites et vouloir les repousser. C’est dans cette découverte/amélioration continue que de nouvelles technos vont pouvoir s’inscrire.
Ça reste super intéressant de tester des choses, de changer de point de vue mais quand on parle de mettre du code en prod, d’autres contraintes doivent être prises en compte :
* Maintenabilité par l’équipe dans le temps ;
* Capacité de répondre efficacement aux problématiques métier sous-jacentes (donc très spécifique au contexte).
Il y a sûrement d’autres choses mais ce sont ces deux points qui sont les plus importants selon moi.
Tant que c’est l’équipe qui fait le choix, qu’il est documenté, compris et intégré par tout les intéressés, je ne vois pas le problème.
Cependant si on commence à intégrer des technos “cool” pour pouvoir draguer des développeurs seniors je pense qu’on glisse du mauvais côté. Un techno est cool sur le papier mais si elle est posé la, sans recul tout développeur qui sera amené à travailler avec va avoir du mal à s’y retrouver.
Alors qu’une base de code un peu plus “chiante” avec des outils old school mais qui est bien structuré, documenté et qui permet de travailler efficacement, aura plus de valeur pour un développeur expérimenté qu’une techno sympa.
D’expérience, je sais qu’il y a toujours la place aux expérimentations donc j’aurais toujours la possibilité de jouer avec un truc ou un autre qui me plaît.
C’est mon avis bien sur, teinté de ce que j’ai pu voir mais ça reste une position très personnelle.